小米在2025年4月30日正式開源了其首個專為推理任務(wù)設(shè)計的大模型Xiaomi MiMo,,此模型以僅7 B參數(shù)的規(guī)模,在數(shù)學(xué)推理(AIME 24–25)和代碼競賽(LiveCodeBench v5)兩大公開評測集上超越了OpenAI的閉源模型o1-mini以及阿里Qwen的32 B參數(shù)預(yù)覽版QwQ-32B-Preview,。
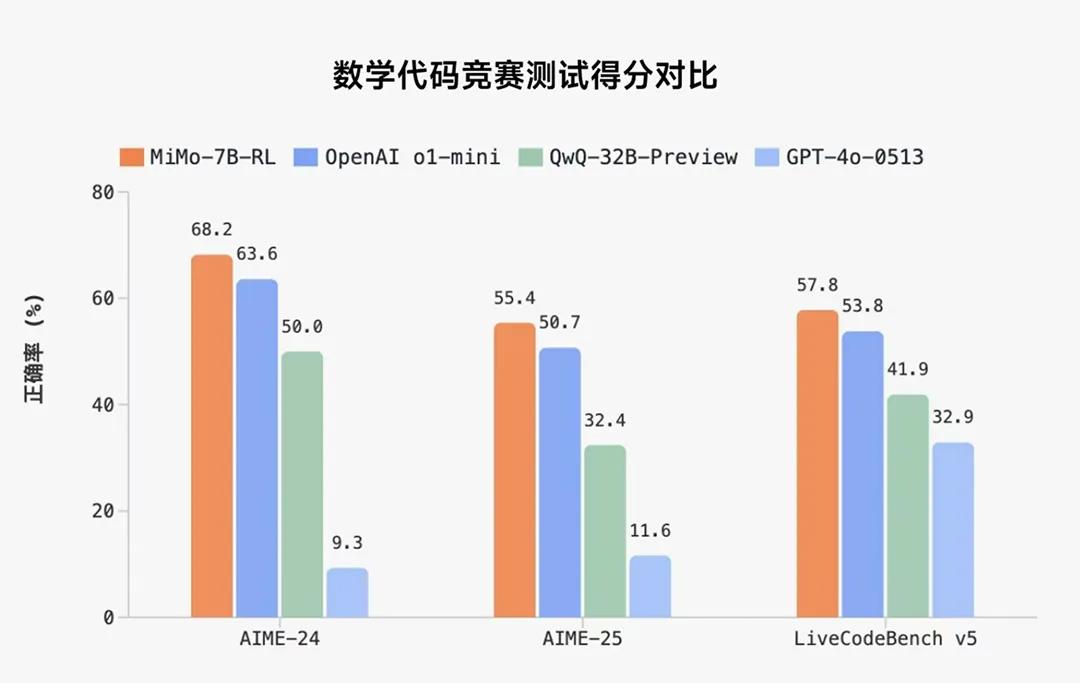
Xiaomi MiMo的推理能力提升得益于預(yù)訓(xùn)練階段對推理模式的深度挖掘和后訓(xùn)練階段算法與框架的多層面創(chuàng)新,。小米團隊首先構(gòu)建了約200 B tokens的專用推理語料庫,,讓模型在更豐富的推理場景中“見多識廣”;在此基礎(chǔ)上,,他們采用三階段遞進式訓(xùn)練策略,,總計訓(xùn)練25 T tokens,以逐步提升模型對復(fù)雜邏輯鏈條的掌握能力,。
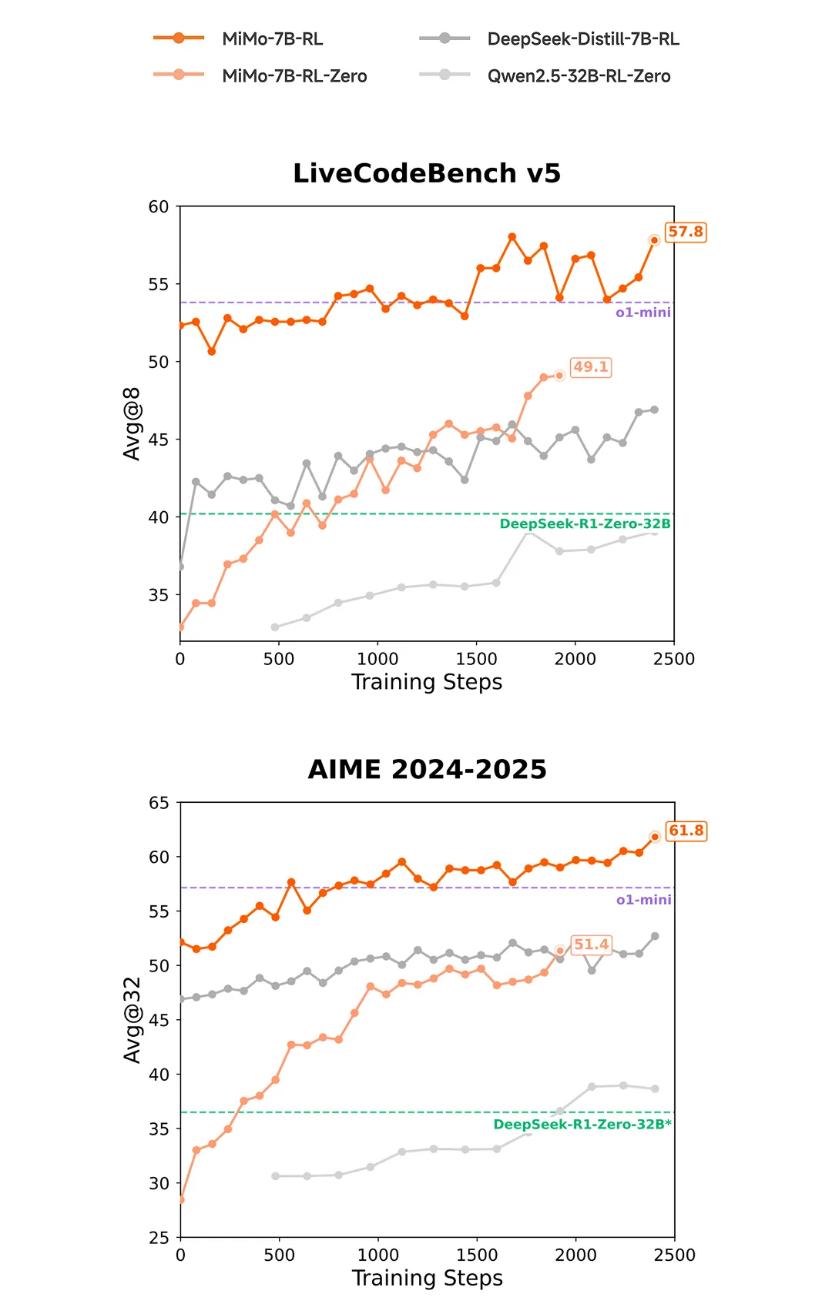
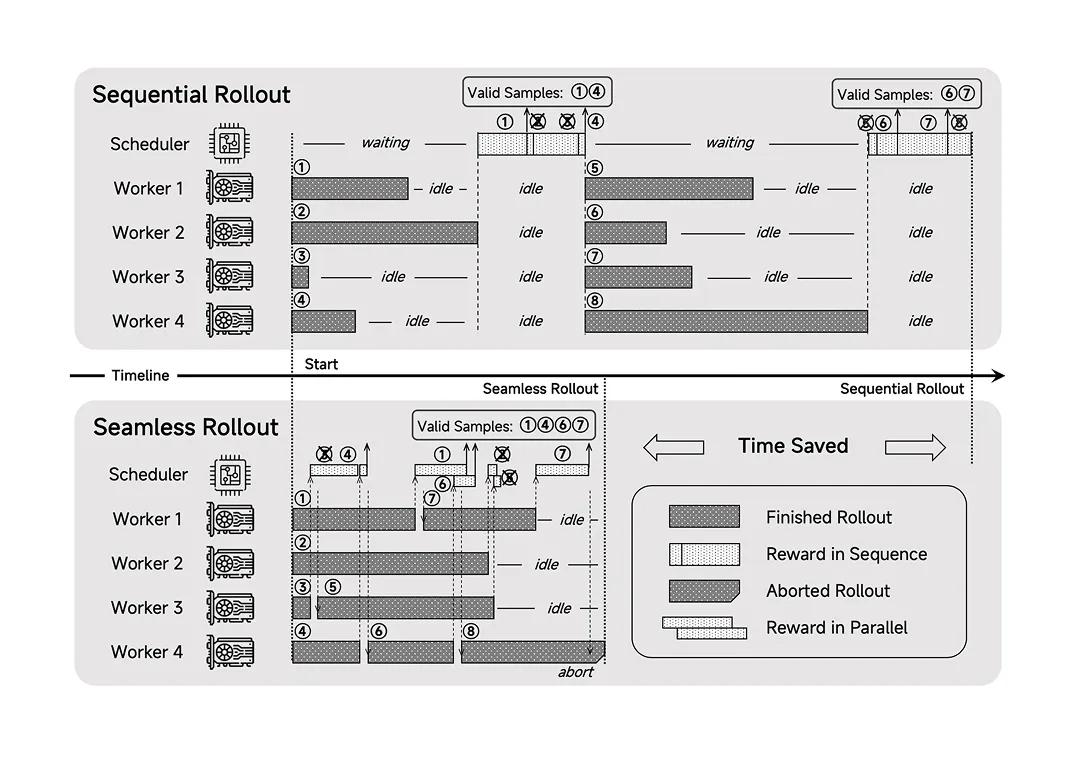
在后訓(xùn)練階段,,團隊引入了“Test Difficulty Driven Reward”算法,以動態(tài)分配不同難度測試樣本的獎勵,從而緩解強化學(xué)習(xí)中常見的獎勵稀疏問題,;同時,,采用“Easy Data Re-Sampling”策略,對較易樣本進行重采樣,,以穩(wěn)定訓(xùn)練過程,,減少梯度更新的跳躍性。為了進一步加速訓(xùn)練效率,,小米還設(shè)計了“Seamless Rollout”系統(tǒng),,將在線生成與批量評估無縫融合,使RL訓(xùn)練速度提升2.29倍,,驗證速度提升1.96倍,。

目前,小米大模型Core團隊已將MiMo-7B系列的四個版本(包括預(yù)訓(xùn)練基線模型MiMo-7B-Base,、監(jiān)督微調(diào)模型MiMo-7B-SFT,、強化學(xué)習(xí)模型MiMo-7B-RL以及零示例強化學(xué)習(xí)模型MiMo-7B-RL-Zero)全部發(fā)布至HuggingFace,技術(shù)報告全文及實驗數(shù)據(jù)也同步開源在GitHub,,內(nèi)容涵蓋模型結(jié)構(gòu),、訓(xùn)練流程、評測指標與對比分析,。
MiMo-7B已開源4個模型至HuggingFace:https://huggingface.co/XiaomiMiMo
技術(shù)報告:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
原創(chuàng)文章,,作者:houxiangyu,如若轉(zhuǎn)載,,請注明出處:http://hzkljs.com/doc/134264.htm












登錄后才能評論