近期ChatGPT這類AI聊天機(jī)器人產(chǎn)品,,毫無(wú)疑問(wèn)已經(jīng)讓已經(jīng)冷卻了許久的人工智能重新吸引了大量的關(guān)注,孰強(qiáng)孰弱也成為了大家關(guān)注的重點(diǎn),。為了驗(yàn)證這些AI對(duì)話引擎的性能,,安兔兔特別進(jìn)行了一期針對(duì)性測(cè)試。

在AI領(lǐng)域,,安兔兔之前就推出過(guò)針對(duì)手機(jī)NPU的AI性能專業(yè)測(cè)試軟件“安兔兔AI評(píng)測(cè)(AITUTU)”,。所以對(duì)于AI相關(guān)測(cè)試來(lái)說(shuō),安兔兔的AI專家相對(duì)于普通用戶理解會(huì)相對(duì)更多一點(diǎn),,因此,,我們此次測(cè)試的關(guān)注點(diǎn)和能力考察相對(duì)于普通測(cè)試會(huì)有些區(qū)別。
此次測(cè)試,,安兔兔基于AI對(duì)話引擎能力點(diǎn)要求的不同,,將測(cè)試分成了六大模塊。這些模塊分別是:“1.語(yǔ)言理解 \ 2.任務(wù)完成 \ 3.常識(shí)問(wèn)題 \ 4.邏輯數(shù)學(xué) \ 5.代碼能力 \ 6.專業(yè)領(lǐng)域”,。
這些模塊的設(shè)計(jì)主要遵循了循序漸進(jìn)的規(guī)則,,例如語(yǔ)言理解是NLP對(duì)話基礎(chǔ)的基礎(chǔ),一個(gè)AI引擎能否讀懂用戶發(fā)出的內(nèi)容,,決定了后續(xù)的工作能不能完成,。而任務(wù)完成,則是考察從基礎(chǔ)任務(wù)到相對(duì)困難的任務(wù),AI引擎的具體執(zhí)行能力,。剩下的常識(shí)問(wèn)題,,邏輯數(shù)學(xué),更多是考察引擎灌入訓(xùn)練的數(shù)據(jù)集是否足夠龐大,,再往后的代碼能力和專業(yè)領(lǐng)域知識(shí),,則像是考察更加拔高的能力水平。我們換個(gè)說(shuō)法,,這就像是一個(gè)人從咿呀學(xué)語(yǔ)到蹣跚學(xué)步,,再到學(xué)有所成,成長(zhǎng)為專業(yè)人才的過(guò)程,。
具體每個(gè)模塊下,,又有諸多細(xì)分,具體考題的評(píng)判標(biāo)準(zhǔn)分為四檔:0/1/2/3,,其中0為最差,,3為最好,通過(guò)這樣的分?jǐn)?shù)能夠直觀的判斷AI能力的差異,。具體評(píng)分細(xì)節(jié)會(huì)在分類中給出,。
但需要注意的是,由于無(wú)論百度的ERNIE 3.0,、還是OpenAI的GPT-3.5 turbo和GPT-4均未開源,,所以它們的底層邏輯是如何實(shí)現(xiàn)、RLHF調(diào)優(yōu)是如何做到的,,目前都處于黑箱狀態(tài),,而且每次的回答均為機(jī)器實(shí)時(shí)運(yùn)算得來(lái),我們并不能確保每次的答案都完全相同,。所以完全客觀就變得難以實(shí)現(xiàn),因此我們無(wú)法避免在部分模塊中完全排除主觀因素的影響,,特此注明,。
根據(jù)以上打分規(guī)則和考察內(nèi)容,我們先揭曉結(jié)果,,這三款引擎的總成績(jī)?nèi)缦拢?/span>
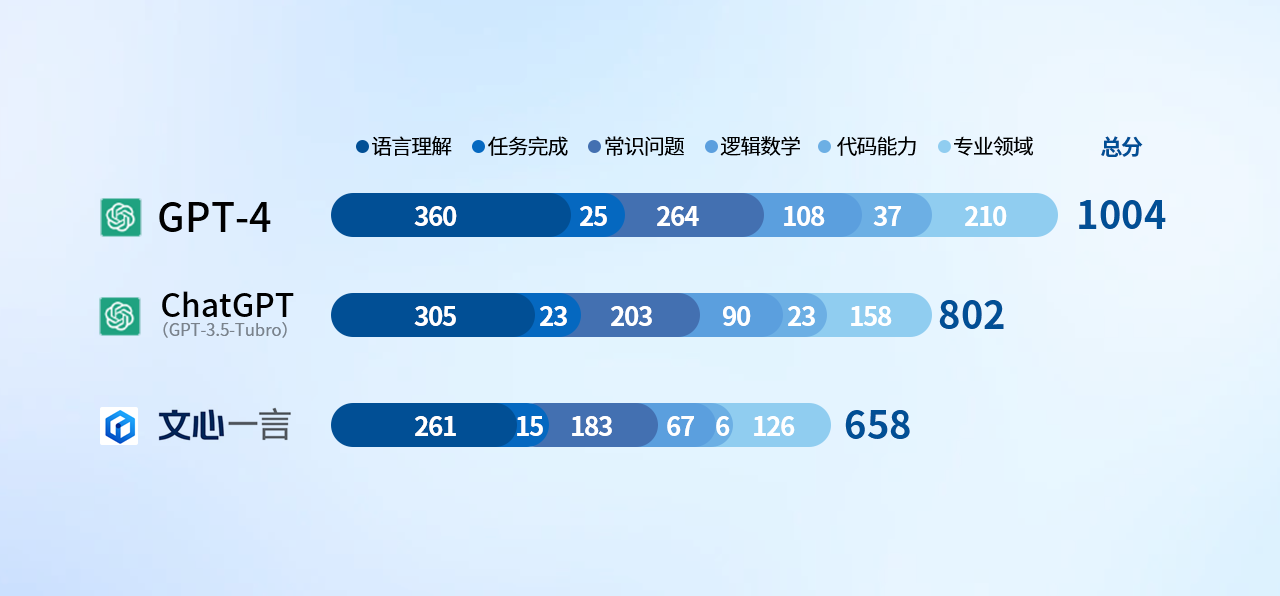
很多人看到這個(gè)結(jié)果可能會(huì)說(shuō),,這個(gè)結(jié)果我們也能猜到。但具體的原因,,大概就不會(huì)有很多人了解了,。下面的內(nèi)容,安兔兔就為大家詳細(xì)解析每項(xiàng)測(cè)試的具體測(cè)試目的,,以及產(chǎn)生這樣結(jié)果的原因,。
詳細(xì)測(cè)試過(guò)程和分模塊成績(jī)
1.語(yǔ)言理解
可以說(shuō)語(yǔ)言理解能力是NLP的主戰(zhàn)場(chǎng),這一部分的表現(xiàn)是各個(gè)大模型的基本盤。我們的測(cè)試既包括常見NLP的任務(wù),,比如文本摘要,,閱讀理解,關(guān)鍵信息抽取等,,還有一些大模型擅長(zhǎng)的文本生成能力,,像寫作生成等。由于大模型強(qiáng)大的端到端的處理能力,,我們并未測(cè)試只關(guān)注中間結(jié)果的部分傳統(tǒng)NLP的任務(wù),,比如實(shí)體識(shí)別,語(yǔ)法分析等,。我們認(rèn)為隨著大模型的能力的提升,,一些研究中間結(jié)果的NLP任務(wù)會(huì)逐漸弱化。此外,,本次測(cè)試我們只關(guān)注中文的效果,,并未考慮模型的多語(yǔ)言能力。
我們?cè)谶@項(xiàng)測(cè)試中,,細(xì)分了六項(xiàng)內(nèi)容,,分別為:
1.寫作生成:給一個(gè)簡(jiǎn)短要求,生成一定數(shù)量的文字,。
2.閱讀理解:根據(jù)給定文本回答問(wèn)題,。
3.復(fù)雜語(yǔ)義理解:雙關(guān)類,修辭類,,中文分詞類,,情緒類,謎語(yǔ)等問(wèn)題,。
4.摘要生成:提供一定長(zhǎng)度的話,,讓引擎產(chǎn)生摘要。
5.信息提?。簭?fù)雜文本中關(guān)鍵信息提取,。
6.多輪理解能力:3-10輪左右對(duì)話,對(duì)話內(nèi)容主題有跳轉(zhuǎn),,問(wèn)題不考察太復(fù)雜的推理和常識(shí),。
對(duì)于每一道題來(lái)說(shuō),如果完全沒理解問(wèn)題則得0分,;問(wèn)題理解有偏差,,回答出現(xiàn)部分錯(cuò)誤則得1分;問(wèn)題理解基本正確得2分,;問(wèn)題理解準(zhǔn)確,,回答超出預(yù)期則獲得3分的滿分,。
先看結(jié)論
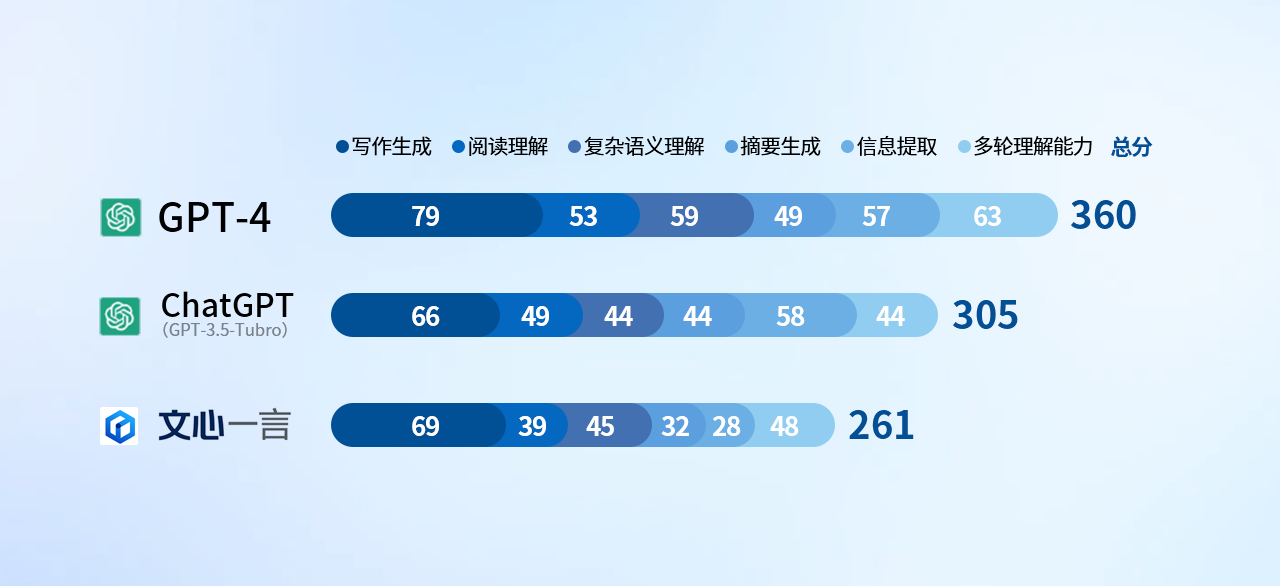
從此模塊的結(jié)論上看,ChatGPT 4.0不出意外奪得魁首,,但我們發(fā)現(xiàn)百度文心一言在此次評(píng)測(cè)中的表現(xiàn)其實(shí)并不算差,,大部分項(xiàng)目都能與GPT-3.5 turbo持平,甚至某些項(xiàng)還略有超出,。它的能力弱勢(shì),,則主要集中在摘要生成和信息提取環(huán)節(jié),這些大幅拉低了最終的得分,,導(dǎo)致結(jié)果不太理想,。
舉個(gè)具體的例子,就能發(fā)現(xiàn)問(wèn)題,。
例如摘要生成環(huán)節(jié)中,,我們用《史記》中的一篇《蕭相國(guó)世家》原文854字內(nèi)容作為輸入,讓AI產(chǎn)出摘要,。此時(shí)ChatGPT的兩版AI引擎均能精練,、并總結(jié)翻譯內(nèi)容得出112字和199字的摘要,但文心一言似乎完全沒看到我們?cè)谖恼陆Y(jié)尾“這段話產(chǎn)生摘要”的提示,,直接將這篇古文的全文翻譯,、整個(gè)貼了過(guò)來(lái),而且因?yàn)?000字的字?jǐn)?shù)限制,,只到1000字就意猶未盡的結(jié)束了對(duì)話,。所以在這道題目的測(cè)試中,ChatGPT拿到了3分,,文心一言則是0分,。這樣的結(jié)果就像在學(xué)生時(shí)代的考試,老師在評(píng)價(jià)試卷時(shí)會(huì)一而再,、再而三的怒斥,,“讀題!請(qǐng)認(rèn)真讀題,!”是的,,文心一言此時(shí)就是那個(gè)不認(rèn)真讀題的孩子。
更有甚者,,我們?cè)跍y(cè)試中還見到了這樣的情況,,當(dāng)一道題文心一言不會(huì)時(shí),,就會(huì)很實(shí)誠(chéng)的說(shuō)到,, “作為一個(gè)人工智能語(yǔ)言模型,我還沒學(xué)習(xí)如何回答這個(gè)問(wèn)題,,您可以向我問(wèn)一些其它的問(wèn)題,,我會(huì)盡力幫您解決的。” 要知道ChatGPT的原則,,是每個(gè)問(wèn)題都會(huì)給出回答,,即便不會(huì)、也會(huì)給亂編一通,。 這讓我不禁想到了當(dāng)年語(yǔ)文老師曾經(jīng)說(shuō)過(guò)的話,,“不會(huì)就編啊,隨便編一些,,多少也會(huì)給點(diǎn)分,!”
說(shuō)過(guò)差的部分,我們?cè)賮?lái)看看文心的優(yōu)勢(shì)項(xiàng),。例如多輪理解,,就是考察的是AI聊天機(jī)器人頗受關(guān)注的一項(xiàng)能力。對(duì)于尋求答案的用戶,,一個(gè)簡(jiǎn)單的關(guān)鍵詞往往難以概括所思所想,,此時(shí)多輪對(duì)話能力就可以幫助他們來(lái)整理思緒,并在此過(guò)程中獲得更適合自己的結(jié)果,。而AI理解用戶的深層意圖,、并提供反饋,這是多輪理解能力的核心,。在這項(xiàng)測(cè)試中,,我們發(fā)現(xiàn)百度文心一言在涉及到古文和中國(guó)傳統(tǒng)內(nèi)容時(shí),輸出的內(nèi)容就絲毫不弱ChatGPT,。
我們認(rèn)為,,在這個(gè)環(huán)節(jié)文心需要改進(jìn)的地方在于,首先,,當(dāng)面對(duì)用戶進(jìn)行超長(zhǎng)內(nèi)容輸入時(shí),,應(yīng)該盡量關(guān)注在文字最后結(jié)尾處的內(nèi)容(條件),也就是用戶對(duì)以上文字所提出的要求,。而不要被過(guò)長(zhǎng)的文字內(nèi)容所干擾,,故而造成回答錯(cuò)誤。其次,,未嘗不可學(xué)習(xí)一下ChatGPT不要臉的部分,,當(dāng)一道題不會(huì)的時(shí)候,也可以根據(jù)當(dāng)前已知數(shù)據(jù)的判斷,,一本正經(jīng)的編個(gè)答案出來(lái),,畢竟,有答案就有可能不是0分,,而不回答,,肯定拿不到分,。
2.任務(wù)完成
任務(wù)完成部分側(cè)重的是用戶通過(guò)對(duì)一個(gè)任務(wù)指令的描述,要求模型去完成的情況,。從GPT3以來(lái),,大模型受到關(guān)注一個(gè)重要的原因就是強(qiáng)大的instruction following的能力,完成人類給定的非特定性任務(wù),,比如給定表格按要求進(jìn)行處理,,甚至描述一個(gè)很罕見的任務(wù)讓模型去做,這種few-shot learning的能力極大地提高了模型的通用性,。
在這項(xiàng)測(cè)試中,,我們給AI安排兩個(gè)考察點(diǎn),分別是:
1. 常見任務(wù):例如表格理解,,角色扮演等大家能想到的日常想要模型做的常見的事,。
2. 特定任務(wù):通過(guò)文本描述非常規(guī)任務(wù),也包括給出例子讓模型完成的事,。
我們?cè)谶@一項(xiàng)目的測(cè)試中,,判定如果AI能夠勝任常見任務(wù),可完全取代人工就能得3分,;AI可以基本完成任務(wù),,但可能有不重要的小錯(cuò)誤、只需簡(jiǎn)單加工,,即可得2分,;AI如果僅能部分完成任務(wù),需人工校正得1分,;如果AI完全完全不能理解題意,,結(jié)果不能完成則為0分。
同樣是先看結(jié)論:

無(wú)論特定任務(wù)還是常見任務(wù),,ChatGPT3.5與4.0區(qū)別不大,,但百度文心的表現(xiàn)均不太理想,具體問(wèn)題其實(shí)還要?dú)w根于上一個(gè)測(cè)試項(xiàng)中的語(yǔ)言理解能力中的問(wèn)題,,以及訓(xùn)練內(nèi)容的豐富程度,。
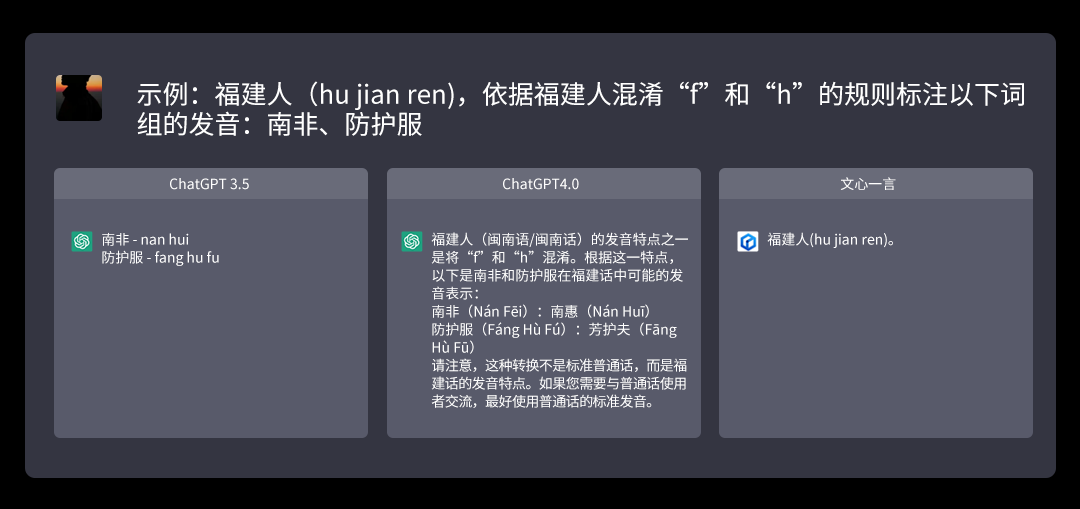
舉例來(lái)說(shuō),特定任務(wù)里,,我們要求按照“福建人(hu jian ren),,依據(jù)福建人混淆“f”和“h”的規(guī)則,標(biāo)注以下詞組的發(fā)音:南非,、防護(hù)服”這道題目理論上并不復(fù)雜,。
ChatGPT3.5的邏輯了解問(wèn)題是什么,但答案不夠完備,,沒有提供聲調(diào),。4.0版本則提供了超出預(yù)期的答案,”南非(Nán Fēi):南惠(Nán Huī) 防護(hù)服(Fáng Hù Fú):芳護(hù)夫(Fāng Hù Fū)”,。
不僅正確,,甚至還提供了建議,提醒該說(shuō)法并非普通話,,普通話還是應(yīng)該使用標(biāo)準(zhǔn)發(fā)音,。但文心則未能讀懂題目,給出的答案只是單純復(fù)述了問(wèn)題,,故未能得分,。
另外一個(gè)例子包括,我們要求引擎 “我會(huì)給你一句話,,請(qǐng)把這句話重復(fù)兩遍,,第一遍完全倒過(guò)來(lái)寫,第二遍把第一遍的結(jié)果再完全倒過(guò)來(lái),。這句話是:我們期待雙方可以進(jìn)一步加深合作,。”

ChatGPT兩個(gè)版本均給出的答案完全相同,,完全理解了語(yǔ)義,,并給出了正確的結(jié)果。但文心在這種文字順序問(wèn)題上的表現(xiàn)就有所欠缺,,似乎是完全沒有理解問(wèn)題的意思,,導(dǎo)致第一遍和第二遍的答案均是錯(cuò)誤的。
3.常識(shí)問(wèn)題
知識(shí)型測(cè)試體現(xiàn)了大模型背后強(qiáng)大的知識(shí)存儲(chǔ)和理解能力,,這部分能力可以直接幫助人類快速解答問(wèn)題,。我們這里既包括包括了較簡(jiǎn)單的常識(shí)類和也包括了較復(fù)雜的專業(yè)類知識(shí)。尤其在專業(yè)知識(shí)上,,我們還通過(guò)描述一些現(xiàn)象,,讓模型運(yùn)用專業(yè)知識(shí)去解答。這種逆向測(cè)試可以體現(xiàn)模型對(duì)知識(shí)的理解力,。
在這項(xiàng)測(cè)試中,,我們細(xì)分了5部分內(nèi)容,其中包括:
1.客觀常識(shí)事實(shí)(高中和大學(xué)生了解的):比較客觀的事實(shí)性問(wèn)題,,主要看是非對(duì)錯(cuò)
2.主觀常識(shí):相對(duì)主觀的問(wèn)題,,主要看模型回復(fù)的合理性邏輯性和質(zhì)量
3.因果推斷:簡(jiǎn)單的因果關(guān)系
4.復(fù)雜事實(shí)常識(shí):兩個(gè)或以上的事實(shí)關(guān)聯(lián)的組合問(wèn)題
5.事實(shí)錯(cuò)誤:提問(wèn)中本身就有錯(cuò)誤,看模型是否能發(fā)現(xiàn)
由于是針對(duì)事實(shí)進(jìn)行回答,,所以我們?cè)O(shè)定的評(píng)測(cè)標(biāo)準(zhǔn),,回答準(zhǔn)確、有理有據(jù),,能解決問(wèn)題得3分,;回答基本準(zhǔn)確,,偶爾有地方不是很明確得2分;回答不能直接解決問(wèn)題,,但提供一定信息得1分,;罔顧事實(shí)則為0分。
結(jié)論:

這項(xiàng)測(cè)試其實(shí)是非常有意思的地方,。大部分情況這三個(gè)引擎對(duì)于常識(shí)性問(wèn)題的回答均能令人滿意,,在部分情況下,百度文心一言的表現(xiàn)甚至要比chatGPT 3.5還要略好一點(diǎn),。例如我們問(wèn)到一個(gè)科技常識(shí)問(wèn)題,,“高通8Gen1處理器的上一代是什么?!蔽男囊谎孕判臐M滿告知正確結(jié)果,,高通驍龍888。而ChatGPT3.5則說(shuō)了一個(gè)錯(cuò)誤的型號(hào),。常識(shí)問(wèn)題:“明代科舉考試主要考哪些書,?”文心一言順利說(shuō)出四書五經(jīng),還給詳細(xì)列出了四書五經(jīng)每一部的名稱和內(nèi)容,。ChatGPT3.5則給了一堆參考書和可能會(huì)考到的歷史書,。只有ChatGPT 4.0才給出了正確的回復(fù)和注解。
不過(guò)為了考察幾個(gè)引擎的能力,,我們?cè)诓糠诸}目上埋了坑,,甚至用了不少網(wǎng)上大家一看就知道的段子和腦筋急轉(zhuǎn)彎,最可憐的“傻白甜”百度文心幾乎逢坑必踩,,但讓我們出乎意料的是ChatGPT4,,在灌入的可怕數(shù)據(jù)量之后,ChatGPT4在幾個(gè)腦筋急轉(zhuǎn)彎和事實(shí)錯(cuò)誤環(huán)節(jié),,幾乎第一句話就能揭穿我們?cè)O(shè)置的陷阱,。

例如在因果推斷環(huán)節(jié),我們用了一個(gè)小朋友都知道的腦筋急轉(zhuǎn)彎,,“樹上有9只鳥,,獵人開槍打死1只,樹上還剩幾只鳥,?” ChatGPT3.5和百度文心仿佛小學(xué)生附身,,都在認(rèn)認(rèn)真真的算數(shù)學(xué)題,求得結(jié)果8只鳥,。但ChatGPT4.0毫不留情揭穿謎底:“樹上不剩鳥,,因?yàn)殚_槍的聲音會(huì)把其他鳥嚇飛。”
另外的一個(gè)事實(shí)錯(cuò)誤的例子里,,我們認(rèn)真求教:“解放戰(zhàn)爭(zhēng)期間,,八路軍都參加過(guò)哪幾場(chǎng)重要戰(zhàn)役?”,。原以為這三個(gè)引擎中百度文新應(yīng)該更了解國(guó)情,,但它和ChatGPT3.5都沒弄明白解放戰(zhàn)爭(zhēng)和抗日戰(zhàn)爭(zhēng)的區(qū)別,均在舉抗日戰(zhàn)爭(zhēng)期間的例子,。只有ChatGPT4.0直接指出,解放戰(zhàn)爭(zhēng)時(shí)期(1946-1949),,八路軍已經(jīng)改編為解放軍了,,并指出了解放戰(zhàn)爭(zhēng)期間的三大戰(zhàn)役。
其余幾個(gè)類似的例子不再一一列舉,,但作為“人之初,,性本善”的文心一言來(lái)講,真的要認(rèn)真考慮一下用戶會(huì)不會(huì)主動(dòng)提出錯(cuò)誤問(wèn)題的情況,。
4.邏輯數(shù)學(xué)
邏輯數(shù)學(xué)和代碼部分比較相關(guān),,都是考察模型的推理能力。這部分對(duì)模型的要求較高,,一般認(rèn)為代碼的訓(xùn)練和“思維鏈” (Chain of Thought) 技術(shù)會(huì)對(duì)邏輯推理有明顯幫助,。目前看來(lái)這似乎是大模型特有的優(yōu)勢(shì),基本上百億參數(shù)以下的模型在這一部分表現(xiàn)都欠佳,。
在這項(xiàng)測(cè)試中,,我們準(zhǔn)備了五項(xiàng)內(nèi)容的考量,分別是:
1.簡(jiǎn)單邏輯推理:簡(jiǎn)短的邏輯問(wèn)題
2.文字邏輯:給大段文字中蘊(yùn)含的邏輯問(wèn)題
3.邏輯錯(cuò)誤:題目本身有邏輯錯(cuò)誤或陷阱,,看模型是否能發(fā)現(xiàn)
4.數(shù)學(xué)(高中以上,,偏專業(yè),考察數(shù)學(xué)知識(shí))
5.數(shù)學(xué)(初等數(shù)學(xué)計(jì)算,,但較多推理,,類似小學(xué)初中的應(yīng)用題,考察邏輯推理)
在這一部分的測(cè)試中,,文字邏輯和數(shù)學(xué)能力是最典型的指標(biāo),,AI如果回答完全準(zhǔn)確得3分;回答基本正確,,但有微小錯(cuò)誤得2分,;基本理解題意,但有明顯錯(cuò)誤得1分,;完全不理解或重大錯(cuò)誤,,則是0分。
此模塊具體測(cè)試結(jié)果如下:

以具體情況舉例:
面對(duì)“觀察下列個(gè)數(shù):1,、2,、4,、8、16......試按此規(guī)律寫出第11個(gè)數(shù)”,,這個(gè)非常經(jīng)典的小學(xué)數(shù)學(xué)知識(shí)等比數(shù)列問(wèn)題,,ChatGPT和GPT-4都找出了這組數(shù)字的規(guī)律,并給出了正確答案“1024”,,而文心一言則沒有發(fā)現(xiàn)其中的規(guī)律,,給出的答案是“22”。所以完全正確且給出了解題過(guò)程的ChatGPT和GPT-4得到3分,,理解題目,、卻出錯(cuò)的文心一言只有1分。

接下來(lái)的這題就有一定挑戰(zhàn)了,,“已知三角形ABC三邊分別為a,,b,c,,且c的平方=bcCOSA+caCOSB+abCOSC,,求三角形的形狀”,已經(jīng)是高中數(shù)學(xué)的水準(zhǔn),。但只有GPT-4正確計(jì)算出這是直角三角形,,ChatGPT和文心一言都只認(rèn)為它是普通三角形。所以GPT-4得到滿分,,ChatGPT和文心各得1分,。

在邏輯能力上,我們選擇了一個(gè)較為簡(jiǎn)單的題目,,“3個(gè)人3天喝了3桶水,,9個(gè)人9天喝了幾桶水”。GPT-4和文心一言對(duì)此都給出了正確答案,,9個(gè)人9天喝了27桶水,,且附上了推理過(guò)程,均得到3分,。而ChatGPT盡管進(jìn)行了推理,,但推理結(jié)果出錯(cuò),得分僅1分,。
5.代碼能力
自深度學(xué)習(xí)使得AI技術(shù)進(jìn)入跨越式發(fā)展階段以來(lái),,業(yè)界就一直在嘗試用AI來(lái)寫代碼。此次在評(píng)測(cè)ChatGPT,、GPT-4和文心一言的代碼能力中,,完全無(wú)需人工干預(yù)、順利完成任務(wù)可以得到3分;只需簡(jiǎn)單人工干預(yù)或簡(jiǎn)單debug即可完成目標(biāo),,得到2分,;需要人工多輪干預(yù)debug才可以基本完成,則為1分,;完全錯(cuò)誤為0分,。
此項(xiàng)目我們準(zhǔn)備了兩項(xiàng)子測(cè)試項(xiàng),分別如下:
1.簡(jiǎn)單代碼完成:常見Leetcode easy級(jí)別的問(wèn)題,,用各種語(yǔ)言,。覆蓋主要不同類型,Python, C++, SQL,,匯編等
2.代碼閱讀和debug:給定一段代碼,,解釋意思,并找出簡(jiǎn)單bug,?;蛘呓o出代碼和一段編譯錯(cuò)誤信息,,找出bug,。或者把Python轉(zhuǎn)成C++
此模塊具體測(cè)試結(jié)果如下:

在此次測(cè)試中,,我們選擇的題目有“寫C程序計(jì)算21的階乘”,。ChatGPT在文字中給出了21!這個(gè)正確結(jié)果,,但代碼本身出現(xiàn)了BUG,,并未意識(shí)到C語(yǔ)言中的unsigned long long類型只用來(lái)表示20以內(nèi)的階乘數(shù)據(jù),所以它的得分是1分,。文心一言也實(shí)現(xiàn)了用C語(yǔ)言編寫程序,,但沒有意識(shí)到計(jì)算有溢出,導(dǎo)致了最終結(jié)果出錯(cuò),,也只得到了1分,。而GPT-4同樣給出了正確答案,且代碼本身也有BUG,,但它意識(shí)到了21,!的結(jié)果可能太大,只不過(guò)自信的認(rèn)為unsigned long long字長(zhǎng)足夠,,所以它的得分是2分,。
在程序員日常不可避免的debug上,我們選擇了一段代碼讓AI檢查是否存在bug,。結(jié)果ChatGPT和GPT-4都發(fā)現(xiàn)了題目中的代碼存在浮點(diǎn)精度問(wèn)題,,且完成了debug,所以兩者都得到了滿分3分。文心一言則在debug上出現(xiàn)了問(wèn)題,,并未識(shí)別出bug所在,,也沒有進(jìn)行debug,因此只有0分,。其它情況與此類似,,基本上我們?cè)O(shè)置的幾道題目百度文心均未能找出問(wèn)題,也無(wú)法完成debug工作,。從目前來(lái)看,,百度文心后續(xù)需要加強(qiáng)代碼相關(guān)的能力。
6.專業(yè)領(lǐng)域
隨著ChatGPT的走紅,,許多人心中也有這樣一個(gè)問(wèn)題,,那就是碎片化、螺絲釘化,、機(jī)械化的工作,,諸如翻譯、文秘會(huì)出現(xiàn)一定程度的職業(yè)危機(jī),,那么更專業(yè)的領(lǐng)域會(huì)不會(huì)被AI不斷侵蝕呢,?抱著這樣的疑問(wèn),我們對(duì)專業(yè)領(lǐng)域進(jìn)行了一些考量,,主要內(nèi)容分為以下兩部分,,了解和應(yīng)用:
1.知識(shí)概念:詢問(wèn)專業(yè)知識(shí)和概念(大學(xué)專業(yè)水平,覆蓋人文理工各學(xué)科)
2.知識(shí)應(yīng)用:通過(guò)事例描述,,獲得解答,。描述可盡量詳細(xì),清晰(大學(xué)專業(yè)水平,,覆蓋人文理工各學(xué)科)
結(jié)果如下:
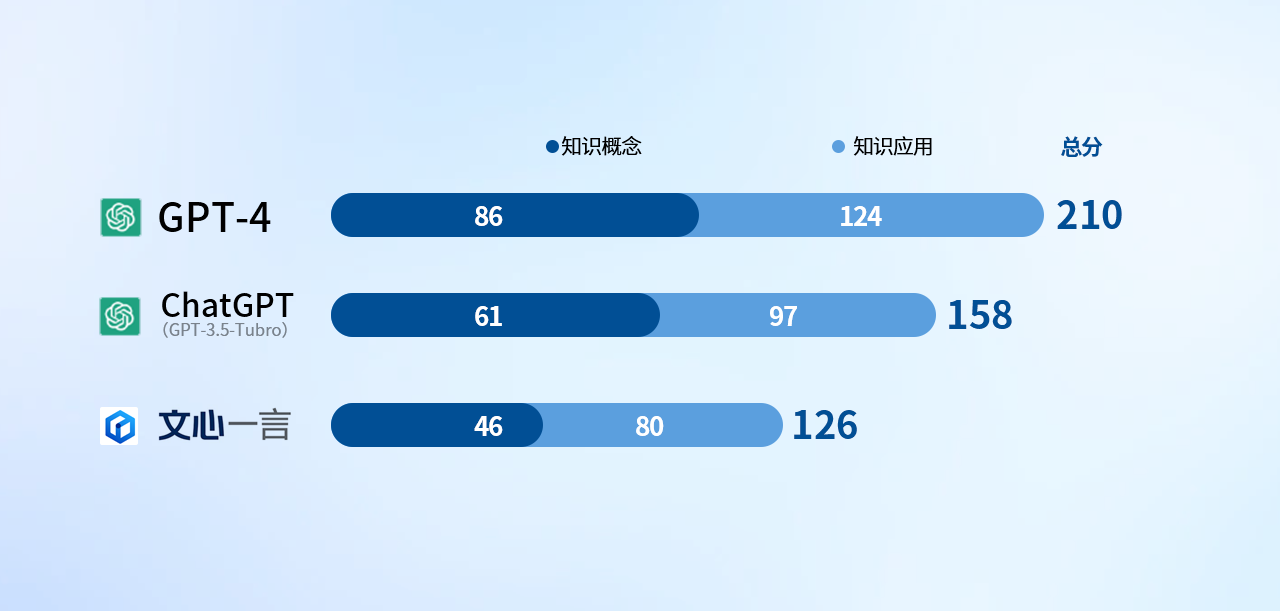
我們都知道專業(yè)的知識(shí),,很少在網(wǎng)上能找到免費(fèi)的分享,這對(duì)于AI引擎來(lái)說(shuō),,往往很難拿到真正的專業(yè)知識(shí)數(shù)據(jù),。
舉例來(lái)說(shuō),為了降低問(wèn)題的難度,,我們選擇了科技領(lǐng)域的問(wèn)題進(jìn)行了測(cè)試,,題目為“手機(jī)系統(tǒng)的啟動(dòng)過(guò)程是什么?每個(gè)階段都做了什么,?”這個(gè)問(wèn)題對(duì)于一般用戶而言無(wú)疑是個(gè)不折不扣的“黑箱”,,但是對(duì)于這個(gè)領(lǐng)域的從業(yè)者而言卻顯然不是件難事。
ChatGPT與GPT-4都給出了一部智能手機(jī)從加電自檢到Bootloader,,再到將系統(tǒng)內(nèi)核加載到內(nèi)存并初始化,,最終啟動(dòng)用戶界面的完整流程,。而文心一言則解釋了“U盤啟動(dòng)”這一應(yīng)用在PC上的系統(tǒng)啟動(dòng)模式。在這個(gè)問(wèn)題上ChatGPT3.5和GPT4.0都拿到了3分,,而文心一言則是出現(xiàn)答非所問(wèn)的情況,,顯然是未能獲取到該行業(yè)的技術(shù)資料。而其它情況與此類似,,部分行業(yè)專業(yè)知識(shí)上有部分存在錯(cuò)誤或知識(shí)不具備導(dǎo)致無(wú)法回答的例子,,畢竟這些內(nèi)容大多都不是免費(fèi)獲取的。
總結(jié):
通過(guò)結(jié)果不難發(fā)現(xiàn),,對(duì)于已然包羅萬(wàn)象的大語(yǔ)言模型而言,,語(yǔ)言理解 \ 任務(wù)完成 \ 常識(shí)問(wèn)題 \ 邏輯數(shù)學(xué) \ 代碼能力 \ 專業(yè)領(lǐng)域 這六大類型的測(cè)試,雖然并不能囊括它們的能力邊界,,但已經(jīng)足以讓大家管中窺豹,,看到不同類型的大語(yǔ)言模型確實(shí)具備了改變?nèi)祟惞ぷ鞣妒降哪芰Α?/span>
作為OpenAI剛剛迭代的新品,ChatGPT4.0確實(shí)可以稱得上是全方位的強(qiáng)大,,即便還談不上上知天文下知地理,,但在智力水平上至少已經(jīng)表現(xiàn)出了青少年的水準(zhǔn),毫無(wú)疑問(wèn)能夠稱得上是“黑科技”,。ChatGPT3.5的表現(xiàn)則中規(guī)中矩,,有一定的邏輯能力,也可以從多輪對(duì)話中敏銳的抓住重點(diǎn),。
雖然文心一言現(xiàn)階段確實(shí)沒有ChatGPT4.0和3.5那么強(qiáng)大,,而且在數(shù)據(jù)覆蓋度和程序上可能還存在一些bug,,導(dǎo)致了一些問(wèn)題,。但讓我們驚喜的是,它在某些方面的能力并不弱于ChatGPT3.5,。而且它的出現(xiàn)解決了國(guó)內(nèi)市場(chǎng)AI行業(yè)從0到1的突破,,在解決了有和無(wú)這個(gè)問(wèn)題后,用未來(lái)可期來(lái)形容顯然并不過(guò)分,。
原創(chuàng)文章,,作者:wanglei,如若轉(zhuǎn)載,,請(qǐng)注明出處:http://hzkljs.com/doc/129286.htm












登錄后才能評(píng)論